Across the Sonic Border
What if the environment you’re in not only acoustically augments your vocal sound but also culturally dictates how you vocally express yourself? An article by Amina Nazari.
INTRODUCTION
Cavernous concert halls are designed to illuminate the sound of every voice in the choir and heavily furnished libraries suppress the chatter of people concealed in their corners. The acoustics of different environments subtly provide thresholds between spaces, not necessarily with physical boundaries, while also implying how one space functions differently to another.
But what if the environment you’re in not only acoustically augments your vocal sound but also culturally dictates how you vocally express yourself.
ACROSS THE SONIC BORDER (VARIATIONS ON 50Hz)
A Metanarrative is a narrative about narratives of historical meaning, experience or knowledge, which offers a society legitimation through the anticipated completion of a (as yet unrealized) master idea. Jean-François Lyotard, a French philosopher, brought the term into prominence in 1984, during the emergence of the post-modernism movement, that occurred across philosophy, the arts, architecture, and criticism.
Lyotard proposed that metanarratives should give way to petits récits, or more modest and ‘localized’ narratives, grounded in the cohabitation of a whole range of diverse and locally legitimated “language-games”. This concept was intended to replace grand narratives by focusing on specific local contexts, as well as on the diversity of human experience, and contend for the existence of a multiplicity of theoretical standpoints rather than have grand, all-encompassing theories.
Accents and regional dialogues are already prevalent in most countries but what if speech were to diversify to start to establish these kinds of language games, as described by Lyotard. We are so proficient at speech and the act of speaking, since we become accustomed to its fundamentals from a very young age. However, it is rare that we stop to consider that speech involves a very complex set of interactions, incorporating much of the body; to produce vowels, consents, intonations and expressions that when combined convey meaning through words and sentences. Speech is an ever-evolving form, just like any other medium, through human manipulation and moulding of its structure; but perhaps speech still has the potential to diversify further and come to more fully exploit human vocal sound. The majority of speech currently exists within a slim tonal range, especially when compared to that of a classically trained tenor; therefore we can imagine alternate human societies with more elaborate vocal communication that utilises our latent vocal ability.
Until recently human speech hasn’t had to negotiate technology. Technology has been proficient in the ability to transmit speech, or other sounds, since the invention of the telephone but, only relatively recently, in the 1990’s, did the vocabulary of a typical commercial speech recognition system succeed the average human vocabulary. Today we can have lengthy conversations with our iPhones enabled by Siri and Samsung smart TV’s come with terms and conditions that warn of talking out-loud in its presence since it may be listening and will transmit this audio data to unlisted 3rd parties. Audio seems to always be foregrounded by it’s more prominent partner: visual media, and we can see this again when we compare the ‘hype’ of emerging face recognition to speech recognition technology.
The visual medium is paramount in many aspects of our culture and we associate it with the ability to identify and denote things, including objects, but also people. Official documents, such as passports, illustrated with our portrait, enable us to traverse geography and join cultures around the world, other than the one we are officially associated to.
But what if the sound of our voices became key markers for our identity and cultural heritage, more so than our visual appearance? Speech recognition technology is fast advancing and becoming more prolific and capable of producing very detailed biometric voiceprints that can describe many aspects of, not only people’s identity but also lifestyle. It’s evolution will soon provide the ability to signify your nationality but also describe where your parents were from and the different places you’ve lived throughout your life, with their associated chimes and inflections imprinted on your oration. Vocal sound, in this capacity, would also determine what countries you’re permitted to visit, just as our passports currently function.
The technology may still be developing but speech recognition tech has already played a role in identification and immigration. Controversially it’s staring to be used by the border agency of the UK and other countries as a way to ascertain the origin of undocumented asylum seekers and utilised to inform decisions about where those individuals can reside. - A highly contentious implementation especially with the voice being particularly fickle and malleable.
By extrapolating the current situation and technological landscape I describe a speculative scenario depicting a future or alternate reality in my project: Across the Sonic Border (Variations on 50Hz). It imagines speech has diversified and nations are split into speech communities, each with their own distinct ways of life as described and defined by their local, vocal dialogue (despite sharing the same language). Returning to Lyotard, his philosophy would imply that by diversifying language this has the potential to diversify the societal culture.
This is a exciting proposition especially when it is further fortified by the Sapir–Whorf hypothesis - an idea in linguistics and cognitive science that holds that the structure of a language affects its speakers' world view or cognition. The strong version of the theory claims that language determines thought and the weak version claims that linguistic categories and usage influence thought and decisions.
But what cultural trigger might influence us to start to become more experimental and radical with the tone of our voices, to potentially lead to the founding of ‘Speech Communities’. Currently society is organised around aesthetic appearance and the idea of ‘truth’ is derived from materials in the visual realm. However, in a society defined and identified by voice the surrounding sonic environment and auditory architecture now become heightened in their cultural influence.
In any indoor space or exterior urban environment, in the UK, a faint hum can be heard – on, around, or a harmonic of 50Hz / G Sharp (60Hz in America) – this is the sound of the Mains Electrical Network Frequency, the persistent accompanying audio of the electricity powering and resonating around our everyday lives. The frequency of the Electrical Network Hum is always oscillating on and around 50Hz and the Electrical Board keep a detailed record of this undulating data. It is therefore possible to take any audio recording, hone in on the Electrical Hum and cross-reference it with the compiled data to pinpoint the date and time of the recording, to almost the exact second. In this way the Electrical Network Frequency Hum forms a watermark on any audio recording and this is already a technique employed by UK police authorities for use in forensics, providing evidence for court cases and upholding the law.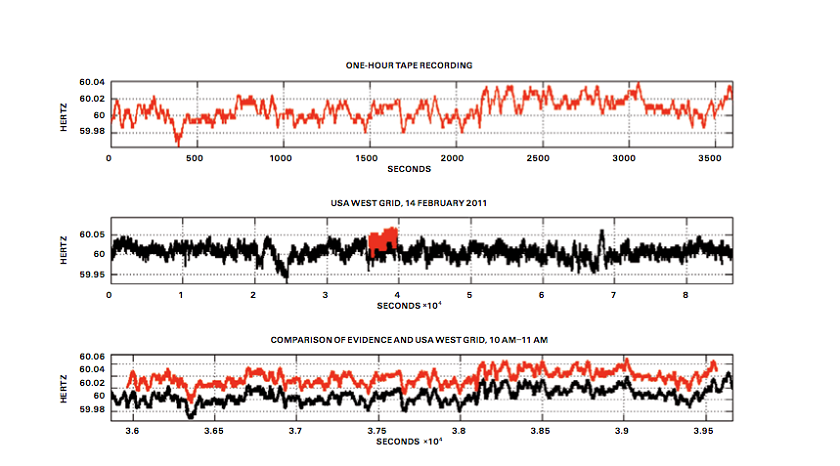 We can imagine, in a society defined by their voices and therefore sonic culture, the pervasive Electrical Network Frequency Hum could become a highly significant, perhaps even authoritative body, where citizens are hyper-aware of its presence and also it’s indicative temporal qualities.
We can imagine, in a society defined by their voices and therefore sonic culture, the pervasive Electrical Network Frequency Hum could become a highly significant, perhaps even authoritative body, where citizens are hyper-aware of its presence and also it’s indicative temporal qualities.
Across the Sonic Border (Variations on 50Hz) is presented as eight audio clips that play through eight headphone jacks in a laser cut map, they can be listened to independently but also provide a linear or chronological narrative. Starting at the Dover border, in scene 1 the Electrical Hum is loudest and most potent, gradually getting quieter through the scenes and having less influence, finally ending in scene 8 where there is no hum. The first two clips set the scene for the overall story. Scene 1 describes what might happen at the border where voice is used for immigration control and to ascertain identity. And concurrently illustrates the speech to song illusion – text manifesting as song in our consciousness through repetition as described by psychologist Diana Deutsch. Next, two petty criminals are anxious that their voices might be recorded with the hum tracing them to the time of the house robbery they’re committing. Scene 3 uses the electrical hum as a marker of the present moment, whereas in Scene 4 the hum marks time but also brings a notion of truth. By scene 5 the hum is not so potent however it is still prominent in collectively joining the community once a week, perhaps similar to the ritual of going to church every Sunday. In scene 6 the faint tone of the hum accompanies highly ornamented vocals for the now exhibitionist act of bartering (inspired by reality TV singing competitions!). Scene 7 describes how someone might receive prohibited speech therapy / vocal coaching for the benefit of code-switching to move across borders. And finally in Scene 8, this rural community live with no hum and have started to borrow from the sound of bird song, perhaps because they’ve forgotten what speech was like before the presence of the hum or perhaps to symbolise their emancipation from technology.
The first two clips set the scene for the overall story. Scene 1 describes what might happen at the border where voice is used for immigration control and to ascertain identity. And concurrently illustrates the speech to song illusion – text manifesting as song in our consciousness through repetition as described by psychologist Diana Deutsch. Next, two petty criminals are anxious that their voices might be recorded with the hum tracing them to the time of the house robbery they’re committing. Scene 3 uses the electrical hum as a marker of the present moment, whereas in Scene 4 the hum marks time but also brings a notion of truth. By scene 5 the hum is not so potent however it is still prominent in collectively joining the community once a week, perhaps similar to the ritual of going to church every Sunday. In scene 6 the faint tone of the hum accompanies highly ornamented vocals for the now exhibitionist act of bartering (inspired by reality TV singing competitions!). Scene 7 describes how someone might receive prohibited speech therapy / vocal coaching for the benefit of code-switching to move across borders. And finally in Scene 8, this rural community live with no hum and have started to borrow from the sound of bird song, perhaps because they’ve forgotten what speech was like before the presence of the hum or perhaps to symbolise their emancipation from technology.
I worked with a speech therapist and creative writer to develop this project. I took on the role of an outlaw speech therapist through my teaching people how to perform their vocal parts, thus giving them ability to code-switch to move across borders, within the narrative. It was important for me that the performers were non-professionals, since part of my work ethic is to encourage a broader range of people to consider the impact of emerging technologies and join the conversation around the implications of their use. I worked with individuals to shape their characters and used a mixture of call and response and improvisation to develop their vocal parts.  The eight audio clips are some-what tongue in cheek but I feel speech and its relationship with technology is about to bring to the forefront a lot of critical issues, especially relating to the built environment, culture and geopolitics. We believe technology and the Internet gives us more opportunities to be heard, express ourselves and facilitate greater freedom of speech. Yet it could be argued that there is actually a crisis of free speech currently breaching in the Western world as we can see with the cases of whistle-blowers Edward Snowden and Chelsea Manning. This para-fictional Across the Sonic Border project presents a synthesis of existing technologies and capabilities that when combined could offer us a new version of reality. I’ve tried to demonstrate, through this project, how new technology integrated into society could give the opportunity for life and culture to diversify and flourish, rather than further a monoculture, which is where we currently appear to be headed.
The eight audio clips are some-what tongue in cheek but I feel speech and its relationship with technology is about to bring to the forefront a lot of critical issues, especially relating to the built environment, culture and geopolitics. We believe technology and the Internet gives us more opportunities to be heard, express ourselves and facilitate greater freedom of speech. Yet it could be argued that there is actually a crisis of free speech currently breaching in the Western world as we can see with the cases of whistle-blowers Edward Snowden and Chelsea Manning. This para-fictional Across the Sonic Border project presents a synthesis of existing technologies and capabilities that when combined could offer us a new version of reality. I’ve tried to demonstrate, through this project, how new technology integrated into society could give the opportunity for life and culture to diversify and flourish, rather than further a monoculture, which is where we currently appear to be headed.
http://cargocollective.com/aminaabbasnazari/Across-The-Sonic-Border-Variations-on-50hz
ABOUT THE ARTIST / AUTHOR
Amina Nazari is a graduate from MA Design Interactions at Royal College of Art, a course that investigates the social, cultural and ethical implications of emerging and future science and technology. She has presented her work at the London Design Festival, Milan Furniture Fair, Venice Architecture Biannual and has lectured at Harvard University, the V&A museum, for industry and prominent NESTA events in London.
She is also a classically trained singer and has sung competitively, internationally with of number of distinguished choirs for 20 years.
Recently Amina has combined her interest and skills in singing and design to utilise sound as a design medium. She is interested in where speech meets sound to blur the boundaries and exploit vocal potential for telling stories about future or alternate realities.
Follow Amina: @AminaNazari
Further Reading:
http://cargocollective.com/aminaabbasnazari/Across-The-Sonic-Border-Variations-on-50hz
https://en.wikipedia.org/wiki/Linguistic_relativity
https://en.wikipedia.org/wiki/Metanarrative
https://en.wikipedia.org/wiki/Electrical_network_frequency_analysis
https://en.wikipedia.org/wiki/Diana_Deutsch
https://en.wikipedia.org/wiki/Code-switching